
Energiekonsum von KI-Chatbots


Warum der Energiehunger von KI-Systemen für visionäre Energieversorger kein Hindernis darstellt
Schweizer Energieversorger stehen vor großen Herausforderungen: steigende Kosten, Fachkräftemangel und ein dynamischer Markt zwingen zu Effizienzsteigerungen und technologischen Innovationen. Besonders im Kundensupport bieten KI-basierte Systeme enormes Potenzial, um repetitive Anfragen automatisiert und präzise zu bearbeiten. Doch während KI-Lösungen wie RAG-Chatbots faszinierende Möglichkeiten eröffnen, werfen Berichte über ihren Energiehunger kritische Fragen auf. Wie lassen sich moderne Technologien nutzen, ohne die ökologische und wirtschaftliche Verantwortung aus den Augen zu verlieren? Der folgende Artikel beleuchtet, wie Energieversorger diese Balance finden können – und welche Rolle ein durchdachtes Datenmanagement dabei spielt.
EVU im Wandel
Schweizer Energieversorger (EVU) stehen vor tiefgreifenden Veränderungen. Regulatorische Vorgaben, steigende Infrastrukturkosten und der Fachkräftemangel erhöhen den Druck, effizienter zu werden und moderne Technologien zu integrieren.
Besonders im Kundensupport bieten sich Möglichkeiten, Kosten zu senken und die Servicequalität zu steigern. Viele Anfragen sind standardisiert und wiederkehrend, weshalb KI-Technologien zur Automatisierung zunehmend an Bedeutung gewinnen. Sie ermöglichen eine schnelle, konsistente Bearbeitung und entlasten Mitarbeitende, die sich auf komplexere Anliegen konzentrieren können.
KI-basierte Chatbots als Lösung
Die Automatisierung des Kundensupports entlastet Energieversorger erheblich. Viele Anfragen betreffen einfache Themen wie Umzugsmeldungen, Rechnungen oder Produktauskünfte und führen zu Spitzenbelastungen, etwa bei Umzügen oder außerhalb der Bürozeiten.
Zusätzlich erschwert die Mehrsprachigkeit in der Schweiz mit vier Landessprachen und vielen fremdsprachigen Kunden den Support. Der Fachkräftemangel verschärft diese Situation weiter.
KI-basierte Chatbots, insbesondere mit Retrieval-Augmented Generation (RAG), sind for diese Herausforderungen wie geschaffen. Sie liefern präzise, kontextsensitive Antworten, unterstützen mehrere Sprachen und können große Anfragevolumina rund um die Uhr bearbeiten – eine Lösung mit großem Potenzial für Effizienz und Kundenzufriedenheit.
Hintergrund
Funktionsweise von LLM und RAG-Chatbots
RAG-Chatbots basieren auf modernster KI-Technologie, die es ermöglicht, natürliche Sprache zu verstehen und präzise Antworten zu geben. Zentral für diese Systeme sind drei Kerntechnologien: Natural Language Processing (NLP), Large Language Models (LLMs) und Retrieval-Augmented Generation (RAG).
Worte als Vektoren - NLP und Embeddings
Um Sprache mathematisch verarbeiten zu können, werden Wörter in sogenannte numerische Vektoren, das sind lange Zahlenfolgen, übersetzt, die ihre Bedeutung in einem mehrdimensionalen Raum repräsentieren. Diese Embeddings ordnen semantisch ähnliche Wörter nahe beieinander an - z. B. liegt “Energie” näher an “Strom” als an “Katze”. Für präzise Modelle ist die Dimensionalität dieser Vektoren hoch, häufig 512 bis 2048 Dimensionen.
Grosse Sprachmodelle (Large Language Models oder LLMs)
LLMs sind große neuronale Netzwerke, die auf Milliarden von Texten trainiert wurden. Sie generieren Antworten, die sowohl grammatikalisch korrekt als auch inhaltlich sinnvoll sind. ChatGPT ist ein bekanntes Beispiel eines grossen Sprachmodells. Allerdings beruhen LLMs auf riesigen Rechenmodellen, die enorme Ressourcen benötigen, insbesondere wenn Nutzer in Echtzeit mit spezifischem Wissen arbeiten sollen.
RAG: Retrieval-Augmented Generation und Wissensdatenbank
RAG kombiniert die Stärken von LLMs mit einer speziell auf das Unternehmen zugeschnittenen Wissensdatenbank. Statt Antworten ausschließlich auf Basis des Modells zu generieren, greift ein RAG-Chatbot auf diese Wissensdatenbank zu, um Antworten mit unternehmensspezifischen Informationen zu ergänzen. Die Wissensdatenbank basiert auf einer sogenannten Vektordatenbank, in der Tausende oder sogar Millionen von Dokumenten als Embeddings gespeichert sind – numerische Vektoren mit einer typischen Länge von 2048. Diese Vektoren ermöglichen es dem RAG-System, die sinngemäss relevantesten Texte zur Nutzeranfrage zu identifizieren und als zusätzlichen Kontext an das LLM weiterzuleiten. Um relevante Inhalte zu finden, wird eine semantische Suche durchgeführt. Dabei wird der Vektor der Nutzeranfrage mit allen Dokumentvektoren in der Datenbank verglichen. Für 10 Millionen Dokumente und eine Vektorlänge von 2048 erfordert dies etwa 81,95 Milliarden Rechenoperationen – allein für eine einzige Anfrage. Dies verdeutlicht den enormen Rechenaufwand, der bei umfangreichen Datenbanken und häufigen Anfragen schnell in einen hohen Energieverbrauch mündet.
Der Energieverbrauch von RAG-Systemen
Trotz des großen Potenzials von RAG-Chatbots im Kundensupport stellt sich eine entscheidende Frage: Wie nachhaltig sind solche Systeme? Schlagzeilen über den Energiehunger moderner KI (McKinsey & Company 2023), der mitunter den Bau eines zusätzlichen Atomkraftwerks rechtfertigen könnte (Yergin 2024), werfen berechtigte Zweifel auf. Besonders für öffentliche EVU, die ökologisch und wirtschaftlich verantwortungsvoll handeln müssen, ist dies ein kritischer Aspekt.
Der Rest dieses Artikels widmet sich der Klärung dieser Frage. Vorweg: Die Effizienz eines RAG-Systems hängt maßgeblich von seiner Architektur ab.
Cloud-Kosten und Energieverbrauch hängen zusammen
Eine präzise Berechnung des Energieverbrauchs von RAG-Systemen ist kaum möglich, da relevante Daten oft fehlen und die Systeme komplex sind. Da jedoch Cloud-Kosten und Energieverbrauch eng gekoppelt sind, lassen sich daraus Annäherungen ableiten. Die wichtigsten Einflussfaktoren sind:
Nutzungsfrequenz: Häufige und komplexe Anfragen verbrauchen mehr Energie als einfache und seltene.
Größe der Vektor-Datenbank: Große Datenbanken mit Millionen Einträgen erfordern erheblich mehr Rechenleistung.
LLM-Modell: Große Modelle wie GPT-4o sind wesentlich energieintensiver als kleinere Varianten.
Näherungsrechnung zur Energieabschätzung
Die Kosten für Cloud-Dienste sind den Betreibern meist bekannt und ermöglichen eine Annäherung an die Energie- und Carbonintensität des Systems.
Energiekostenanteil von Cloud-Diensten: Studien zufolge entfallen zwischen 46% (International Data Corporation 2023) und 70% (BLS Strategies 2023) der Kosten auf Energie. Bei LLMs könnten die Anteile noch höher liegen da OpenAI aktuell höhere Kosten als Einahmen hat (RightAI 2023). Die geschätzten Energiekostenanteile sind:
Vektordatenbank (compute, storage): 45% der verrechneten Kosten.
LLM-Modell: 70% der verrechneten Kosten.
Berechnung des Energieverbrauchs via Stromtarife: Großverbraucher wie Datenzentren zahlen etwa 8 Rappen (Reddit 2023) bis 15 Rappen (Württembergische Energie 2023) pro kWh, was eine Ableitung des Energieverbrauchs ermöglicht.
CO₂-Intensität des Strommixes: Diese variiert je nach Standort:
Schweiz: 40 g CO₂/kWh (Bundesamt für Umwelt 2023).
Deutschland: 400 g CO₂/kWh (Statista 2023).
Obwohl ungenau, bietet diese Methode eine Grundlage, um verschiedene Szenarien und die Größenordnung des Energieverbrauchs zu bewerten.
Vergleichsszenarien
| Metric | Small | Medium | Large |
|---|---|---|---|
| Storage Cost ($ month) | 0 | 0 | 19 |
| Compute Cost ($ month) | 4 | 42 | 3'000 |
| Operational Cost ($ month) | 60 | 60 | 60 |
| Total Vector Cost ($ month) | 64 | 102 | 3'079 |
| Total LLM Cost ($ month) | 0 | 25 | 1'712 |
| Energy Cost Vector ($ month) | 29 | 46 | 1'385 |
| Energy Cost LLM ($ month) | 0 | 17 | 1'199 |
| Total Energy Cost ($ month) | 29 | 63 | 2'584 |
| Total Energy Use (kWh year) | 3'169 | 6'919 | 281'916 |
| Total CO₂ (kg year) | 127 | 277 | 112'767 |
Zur Einordnung zeigt die nebenstehende Tabelle drei Szenarien mit unterschiedlichen RAG-Systemen:
Small: Optimierte Datenstruktur, idealer Serverstandort, moderate Nutzerzahl.
Medium: Optimierte Datenstruktur, idealer Serverstandort, hohe Nutzerzahl.
Large: Suboptimale Datenstruktur, suboptimaler Serverstandort, hohe Nutzerzahl.
Die Unterschiede sind erheblich: Der jährliche Energieverbrauch kann zwischen 3’169 kWh und 281’916 kWh reichen. Beim CO₂-Fussabdruck ist der Unterschied mit einem Faktor von 890 sogar noch grösser. Bemerkenswert ist, dass nicht die Nutzerfrequenz, sondern die Datenstruktur den größten Einfluss hat – sichtbar im Vergleich von Medium und Large. Effiziente Datenoptimierung ist somit ein zentraler Hebel zur Reduktion von Energieverbrauch und Kosten.
Auswirkungen des Energiehungers von RAG-Systemen
Es zeigt sich, dass der Energieverbrauch von RAG-Systemen stark variieren kann. Doch wie relevant ist dieser Energieverbrauch in der Praxis, und welche Konsequenzen könnte er für Unternehmen und die Gesellschaft haben?
Vergleich auf Unternehmensebene
Laut Energie.ch (2023) verbraucht ein Büroarbeitsplatz in der Schweiz durchschnittlich 120 kWh pro Jahr und Quadratmeter. Bei einer Fläche von etwa 12 Quadratmetern pro Mitarbeiter ergibt dies einen Energieverbrauch von rund 1’440 kWh pro Mitarbeiter jährlich.
Ein effizienter RAG-Chatbot mit optimaler Datenstruktur kann die Arbeit von etwa 1 bis 3 Mitarbeitern übernehmen, während weiterhin Personal für Aufgaben wie Telefonservice benötigt wird. In diesem Szenario bleibt der Energieverbrauch des Unternehmens durch den Einsatz eines Bots nahezu unverändert.
Ein ineffizientes RAG-System hingegen kann drastische Auswirkungen haben. Bei einem Unternehmen mit 100 Mitarbeitern könnte der Energieverbrauch des gesamten Unternehmens durch die KI-Technologie leicht verdoppelt werden (nur Bürogebäude). Noch gravierender ist die potenzielle Verschlechterung der CO₂-Bilanz, insbesondere wenn auf Strom aus einem „schmutzigen“ Energiemix außerhalb der Schweiz zurückgegriffen wird.
Vergleich auf Landesebene
Wenn ineffiziente RAG-Systeme nur von wenigen Unternehmen eingesetzt werden, wäre der Einfluss auf die Schweiz gering. Doch diese Hoffnung trügt: Die schnelle Verbreitung von KI-Technologien wie RAG-basierten Chatbots führt dazu, dass in der Schweiz künftig zwischen 10’000 und 15’000 Unternehmen solche Systeme nutzen könnten.
Die Schweiz verzeichnete 2023 einen CO₂-Ausstoß von 34.74 Millionen Tonnen. Würden 10’000 Unternehmen ineffiziente RAG-Systeme einsetzen, könnte dies zu einem zusätzlichen Ausstoß von etwa 1.128 Millionen Tonnen führen – ein Anstieg um 3 %. Dies wäre sowohl für die Umwelt als auch für die Gesellschaft kaum akzeptabel.
Der Einsatz effizienter und optimierter KI-Bots hingegen würde den zusätzlichen CO₂-Ausstoß auf nur 0.001 Millionen Tonnen begrenzen. Wie oben dargestellt, ist dies kein Mehrverbrauch verglichen mit normaler wirtschaftlicher Aktivität. Damit wird klar: Die Effizienz der Systeme ist der Schlüssel zur nachhaltigen Einführung moderner KI-Technologien bei EVU.
Hintergrund
Das Ende des Dennard Scaling und der Energiehunger der KI
Die Grenze der Effizienzgewinne
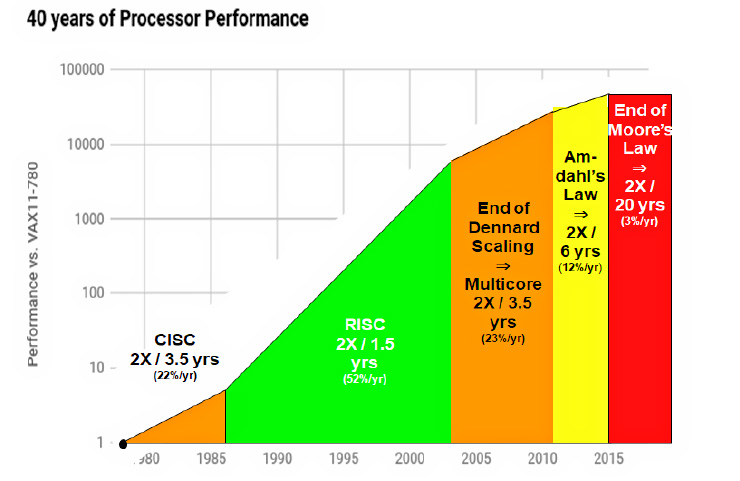
In den letzten 40 Jahren profitierte die IT-Industrie davon, dass Siliziumschichten in Computerchips kontinuierlich dünner wurden, was es ermöglichte, bei gleichem Energieeinsatz immer mehr Rechenleistung zu erzielen. Dieser Effekt, bekannt als Dennard Scaling, führte dazu, dass sich die Leistung von Chips etwa alle zwei Jahre verdoppelte. In den letzten Jahren stößt diese Entwicklung jedoch an physikalische Grenzen, da Siliziumschichten mit einer Dicke von nur noch 2 nm – das entspricht 8 bis 10 Molekülschichten – das Machbare nahezu ausschöpfen (Barry 2019). Die Folge: Weitere Leistungssteigerungen gehen nicht mehr mit Effizienzgewinnen einher, sondern erfordern höhere Energie. Statt effizienter zu werden, werden Chips durch Clusterung immer größer, was den Energieverbrauch weiter steigert.
Größere Modelle
Parallel dazu wachsen die Anforderungen durch immer größere Modelle. Moderne LLMs benötigen nicht nur mehr Daten, sondern auch eine exponentiell steigende Anzahl von Parametern, um bessere Ergebnisse zu erzielen. Dies folgt dem Neural Scaling Law, welches zeigt, dass der Trainingsaufwand mit der Modellgröße überproportional zunimmt (Kaplan et al. 2020).
Lösung: Datenzentrierte RAG-Systeme
Nachdem gezeigt wurde, wie entscheidend die Energieeffizienz von RAG-Systemen für Unternehmen ist, stellt sich die Frage, wie solche effizienten Systeme erreicht werden können. Die Lösung liegt in einer Kombination aus optimierter Datenqualität und der strategischen Auswahl kleinerer Modelle und Kontexte. SwissDataApps nennt diese Systeme datenzentrierte RAG-Systeme
Fokus auf Datenqualität
Ein zentraler Ansatz für effiziente RAG-Systeme ist die gezielte Verbesserung der Datenqualität, sodass die Wissensdatenbank mit kleineren, aber wesentlich relevanteren Datenmengen auskommt. Bei vielen Firmen gibt es hier großes Potenzial, da häufig folgende Probleme auftreten:
- Doppelte oder redundante Informationen: Gleiche Inhalte werden in verschiedenen Dokumenten mehrfach gespeichert.
- Widersprüchliche Informationen: Unterschiedliche Dokumente enthalten inkonsistente oder gegensätzliche Aussagen.
- Veraltete Daten: Informationen sind nicht mehr aktuell oder haben ihren Nutzen verloren.
- Irrelevante Inhalte: Viele Informationen sind für die Kundenanfragen oder das Ziel der Wissensdatenbank unbedeutend.
Der aktuelle Standardansatz, „blind“ alle verfügbaren Daten in die Wissensdatenbank zu integrieren, führt zu übergroßen und ineffizienten Systemen. Diese benötigen mehr Speicherplatz, erhöhen den Rechenaufwand und steigern den Energieverbrauch erheblich. Der Effizienzgewinn durch gute Datenqualität ist jedoch enorm: Für jeden schlechten oder falschen Datensatz müssten im Schnitt 100 gute Datensätze hinzugefügt werden, um die gleiche Genauigkeit zu erreichen. Eine sorgfältige Datenaufbereitung ist daher ein entscheidender Hebel, um die Leistung der Systeme zu optimieren und gleichzeitig Ressourcen zu schonen.
Verwendung von kleineren Modellen und Kontexten
Die Verbesserung der Datenqualität und der Fokus auf relevante, präzise Informationen ermöglichen den Einsatz kleinerer Modelle. Ein Wechsel von einem großen Modell wie GPT-4 Turbo zu einer kompakteren Variante wie GPT-4-mini kann Einsparungen von bis zu Faktor 60 bei Kosten und Energieverbrauch erzielen. Dies wird möglich, weil die mitgelieferten Kontextinformationen aus der Wissensdatenbank den Inhalt der Antwort bereits gezielt abdecken. Statt auf ein möglichst großes Modell mit breiter Trainingsbasis angewiesen zu sein, wird das LLM primär genutzt, um die vorgegebenen Informationen in gut formulierte Antworten umzuwandeln.
Darüber hinaus erlauben präzisere und besser strukturierte Daten, die Texte in der Wissensdatenbank kompakter zu halten. Dies verringert die Anzahl der sogenannten Input-Tokens, die bei jeder Anfrage verarbeitet werden müssen, was die Rechenzeit weiter reduziert. Effizienz entsteht somit nicht nur durch die Wahl eines kleineren Modells, sondern auch durch eine optimierte Datenstruktur, die Kosten und Energieverbrauch erheblich minimiert.
Hintergrund
KI-Trend: mehr Datenqualität statt Big Data
Andrew Ng’s datenzentrierte KI
Andrew Ng, ein führender KI-Forscher, Stanford Professor und Visionär, propagiert mit seiner data-centric AI den Paradigmenwechsel, den Fokus von immer größeren Modellen auf hochwertige Daten zu verlagern. Anstatt die Komplexität der Modelle weiter zu erhöhen, betont er, wie entscheidend sauber kuratierte, konsistente und relevante Daten für die Leistungsfähigkeit von KI-Systemen sind. Dieser Ansatz zeigt, dass durch bessere Daten oft kleinere und effizientere Modelle ausreichen, um herausragende Ergebnisse zu erzielen. Dieses Konzept wurde bisher noch nicht auf die RAG-Technologie angewendet, hat aber grosses Potential. Data-centric AI würde nicht nur Genauigkeit optimieren, sondern auch gleichzeitig den Energieverbrauch und die Betriebskosten reduzieren.

Less than one-shot Learning (MIT Technology Review 2020)
„Less than one“-shot (LO-shot) Learning zeigt, dass der Fokus nicht auf immer größeren Datenmengen liegen muss, sondern auf wenigen, hochinformativen und gezielt optimierten Datenpunkten. Durch die Nutzung sogenannter „soft labels“, die mehrere Klassen in einem einzigen Datenpunkt kombinieren, können Modelle trainiert werden, die mit minimalem Dateneinsatz genauso leistungsfähig sind wie solche, die auf riesigen Datensätzen basieren. Für RAG-Wissensdatenbanken bedeutet dies, dass statt großer, redundanter Vektorstrukturen gezielt verdichtete und editierte Daten verwendet werden könnten.
Vorteile eines datenzentrierte RAG-Systems
Ein datenzentrierter Ansatz für RAG-Systeme bietet zahlreiche überzeugende Vorteile:
- Genauere Antworten: Minimierung des Risikos von veralteten, widersprüchlichen oder irrelevanten Informationen in der Wissensdatenbank.
- Kosteneinsparungen: Weniger Daten und effizientere Systeme bedeuten geringere Cloud- und Betriebskosten.
- Verantwortungsvoller Energieverbrauch: Effiziente Systeme ermöglichen den Einsatz moderner Technologie mit einem geringeren ökologischen Fußabdruck – ein entscheidender Faktor für öffentliche Energieversorger, die eine Vorbildrolle einnehmen müssen.
- Zukunftssicherheit: Mit einem datenzentrierten Ansatz sind Unternehmen vorbereitet, falls gesetzliche Vorgaben oder öffentliche Erwartungen den Energieverbrauch von Datensystemen stärker regulieren.
SwissEnergyBot – Der datenzentrierte RAG-Chatbot für Schweizer EVU
Der SwissEnergyBot, entwickelt von SwissDataApps in Zusammenarbeit mit Partnern, setzt das datenzentrierte RAG-Konzept speziell für Energieversorger um. Er kombiniert eine bereits optimierte allgemeine Wissensbasis zur Energiewirtschaft und Energietechnologie mit individuell angepasstem Wissen des jeweiligen EVU, wie z. B. spezifischen Tarifen oder Prozessen. Beide Datenebenen – sowohl die allgemeine als auch die spezifische – werden semiautomatisch bereinigt, optimiert und getestet, um höchste Präzision und Effizienz zu gewährleisten.
Das optimierte Wissen wird schließlich in ein fein abgestimmtes Multi-Agent-RAG-System eingebettet. So gewährleistet der SwissEnergyBot höchste Antwortqualität, faktenbasierte Ergebnisse und einen verantwortungsvollen Energieverbrauch – ideal für EVU, die Effizienz und Nachhaltigkeit in Einklang bringen möchten.
References
Barry, Daniel Joseph. 2019. “Beyond Moore’s Law: New Solutions for Beating the Data Growth Curve.” https://www.microcontrollertips.com/beyond-moores-law-new-solutions-beating-data-growth-curve/.
BLS Strategies. 2023. “Power Requirements, Energy Costs, and Incentives for Data Centers.” https://www.blsstrategies.com/insights-press/power-requirements-energy-costs-and-incentives-for-data-centers.
Bundesamt für Umwelt. 2023. “Klimawandel: Fragen Und Antworten.” https://www.bafu.admin.ch/bafu/de/home/themen/klima/fragen-antworten.html.
Energie.ch. 2023. “Stromverbrauch Im Büro.” https://energie.ch/buero/.
International Data Corporation. 2023. https://www.idc.com/getdoc.jsp?containerId=prUS52611224.
Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. “Scaling Laws for Neural Language Models.” arXiv Preprint arXiv:2001.08361. https://arxiv.org/abs/2001.08361.
McKinsey & Company. 2023. “How Data Centers and the Energy Sector Can Sate AI’s Hunger for Power.” https://www.mckinsey.com/industries/private-capital/our-insights/how-data-centers-and-the-energy-sector-can-sate-ais-hunger-for-power.
MIT Technology Review. 2020. “AI Machine Learning with Tiny Data.” https://www.technologyreview.com/2020/10/16/1010566/ai-machine-learning-with-tiny-data/.
Reddit. 2023. “How Much Do Data Centers Pay for Power?” https://www.reddit.com/r/datacenter/comments/15pp9rl/how_much_do_data_centers_pay_for_power_do_they/?tl=de&rdt=36887.
RightAI. 2023. “OpenAI Erwartet Verluste von 5 Milliarden Dollar: Rechenleistungskosten Machen 80.” https://right-ai.com/de/blog/post/caee6c1e272e4297b4ea7acffa67286e.
Statista. 2023. “CO₂-Emissionsfaktor Für Den Strommix in Deutschland Seit 1990.” https://de.statista.com/statistik/daten/studie/38897/umfrage/co2-emissionsfaktor-fuer-den-strommix-in-deutschland-seit-1990/.
Württembergische Energie. 2023. “Energy Calculator.” https://www.wuerttembergische-energie.de/energy-calculator.
Yergin, Dan. 2024. “Big Tech Is Driving a Nuclear Power Revival, Energy Guru Dan Yergin Says.” CNBC. https://www.cnbc.com/2024/10/23/big-tech-is-driving-a-nuclear-power-revival-energy-guru-dan-yergin-says.html.